HBase and Cassandra: Which database to select?

Choosing the most efficient database management system is essential for obtaining streamlined operations and a consistent development process. In the age of significant rise in Data Science and Big Data Analytics, the scalability and speed of NoSQL databases are especially valued by programmers.
At PNN Tech, we often answer the question of which database works more seamlessly and effectively within a particular Big Data project – it’s HBase vs Cassandra topic, in other words. However, many details related to performance and architecture should be considered to give a proper answer. Let us start our comparative review by considering the basics of both systems.
Both NoSQL databases are open-source and widely utilised as data stores. The architecture of Apache Cassandra was modelled after Bigtable and Amazon’s DynamoDB, while HBase architecture was created to run on HDRS in Hadoop systems. The first database serves as an example of a key-value data store containing ordered column entries. Apache also consists of columns with frequent attributes you can access promptly; the system is ordered and indexed, simplifying reading data.
Among the well-known companies utilising Apache Cassandra are Apple, CVS Health and Verizon Wireless. Some of the market leaders who implemented Apache HBase are Bank of America, JP Morgan Chase and American Express.
HBase has a column-oriented Table at its top level. Each table has sets of row keys, which would be primary keys in a traditional relational database. HBase divides rows into column families – related data columns.
As for Cassandra’s data model, it can be described as a partitioned row store. At its top level is the Keyspace with tables (column families). Within a column family, rows are stored on a single disk.
HBase supports authorisation and authentication: the former can be restricted to the cell level when necessary. Kerberos authentication on the cluster allows for robust client encryption.
Likewise, Cassandra supports authentication and authorisation. Access to some records might be restricted depending on the staff member’s role. Within Cassandra 4+, the company’s administration can see the sequence of actions performed on particular data through audit logging.
Since Cassandra is explicitly created for massive and large-scale data ingestion, it enables one to write data faster, simultaneously cache and log. HBase needs to interact with ZooKeeper and HMaster to define where information should be placed, making this database’s performance slower.
Additionally, Cassandra tends to read data slower, as it has to be retrieved via nodes holding information. Possessing HDFS underpinnings with caches and bloom filters, Hbase reads data more promptly.
The feature of ACID transactions in HBase is still in beta. In comparison, Cassandra does not support transactions so far and does not have rollback capability. However, you can still use lightweight transactions, which implies updating records.
Regarding Query Language, Cassandra has CQL – a SQL-like language allowing for selecting, inserting, deleting and updating records. Yet, it needs to be kept in mind that not sufficiently optimised queries may harmfully impact cluster performance. CQL can be utilised either with Cassandra cluster or Apache Cassandra client libraries.
HBase shell can be considered the closest alternative to a query language; users may interact with data via put, create, scan, and other commands. In the case of adding Apache Phoenix language, you will get an impression of a SQL-like query language. PNN Soft experts utilise Java API within the HBase cluster to obtain expanded possibilities to insert, create and update significant data sets.
HBase contains HDFS for data replication, which being rack-aware, prioritises different network servers. As a result, the system prevents data loss and tolerates a single network outage.
In Cassandra, replication settings are placed on individual keyspaces, and some can also be rack aware. However, conversely, Cassandra does not possess a master node or primary replica for a particular record. The system is remarkable for its data centre – defining racks/sets of nodes in a specific geographical region. The data model comprises either one or multiple data centres with possible replications among them.
In other words, you possess a single database with various localities, resulting in lower latency and better data consistency across different regions.
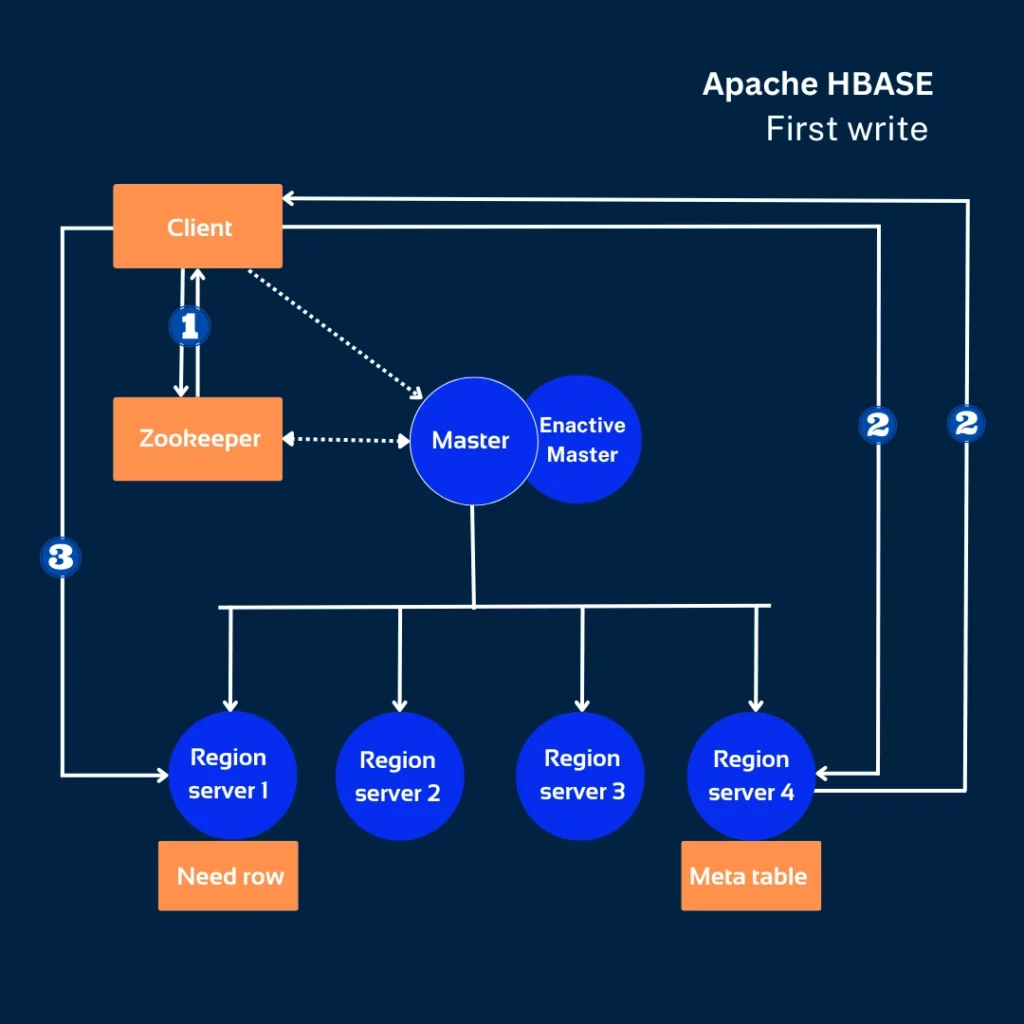
PNN Soft developers may scale up HBase by adding extra nodes to cluster, frequently, region servers. The system will split data sets into new regions if the volume is too massive. Hence, adding regional servers is a key to more efficient load distribution.
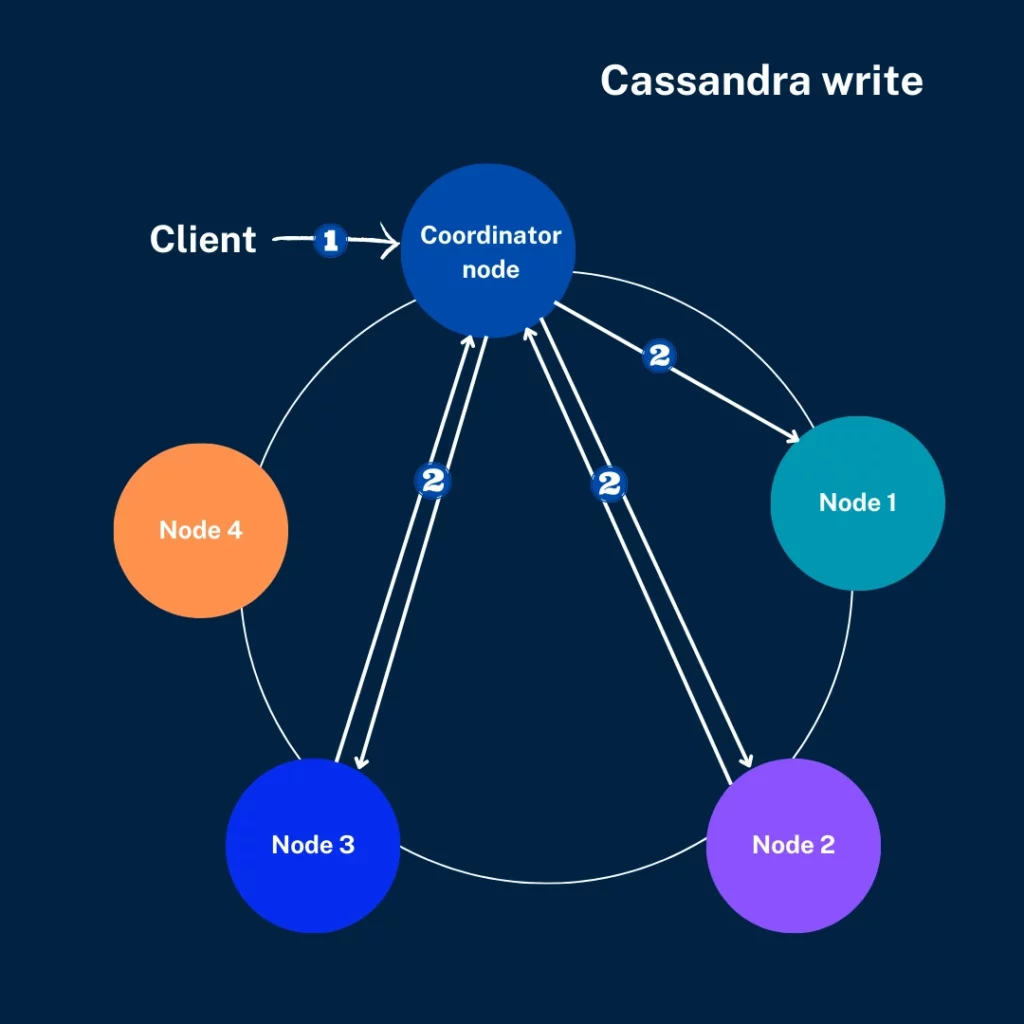
As Cassandra contains a consistent hash for data partition in the cluster to the nodes within, newly created nodes lead to immediate data distribution. Several factors are critical for the amount of data: replication settings, total data amount, number of nodes, etc.
Cassandra can also be scaled by adding additional nodes to the cluster. Cassandra uses a consistent hash to evenly partition the data in the cluster to the nodes within. Adding new nodes to a cluster immediately distributes data to that node. The amount of data depends on numerous factors, such as how much total data exists in the cluster, the number of nodes, replication settings, etc.
Both HBase and Cassandra were designed to be distributed databases and can scale to hundreds of nodes effectively.
As we implicitly mentioned, both systems aim at storing and handling large data sets. We advise using HBase to take full advantage of HDFS underpinnings and Hadoop. It is especially helpful for the Healthcare, Telecom and Finance sectors.
Cassandra, for its part, shines where your company needs to store lots of data promptly. For instance, when storing large data sets is crucial, and you would need to access them less frequently. One example of such a tendency is the Internet of Things technology.
HBase will be the most logical choice if you need to take advantage of Hadoop features (e.g. MapReduce). However, if you are directed towards streamlining infrastructure deployment, Cassandra will be more beneficial for your company. The same applies if you need to operate with data replication between geographical regions: native support is embedded into Cassandra.
From PNN Soft experience, another advantage of Cassandra is higher support by a community of consultants – both with the cloud or on-prem solutions, in cases of clusters malfunctioning, etc.
We hope to give you some clarity on the question of which database to select. If you need further consultancy on the difference between HBase and Cassandra in line with your business objectives, please, don’t hesitate to contact the PNN Soft team.

