Unleashing the potential of AI: a step-by-step guide to implementing AI algorithms in Python

Applying Python to AI algorithms opens up huge possibilities for seasoned programmers and promising specialists at the beginning of their professional journey. The field of AI is growing rapidly and covers various solutions in marketing, e-commerce, healthcare, transportation and other business sectors. Therefore, a vast number of tools and libraries specifically provided for Python software development and AI implementation are essential to learning in the contemporary IT landscape.
This post will touch upon the benefits of applying Python for Artificial Intelligence, libraries and strategies for implementing AI algorithms consistently. Without further ado, let us start.

Even though Python already possesses built-in functions to successfully operate with AI, some Artificial Intelligence libraries will nonetheless be helpful for enhancing the capacities of your future solution:
First things first: you need to define the issue as precisely as possible. This implies understanding the data you work with and possible constraints occurring along the way towards your objective. Once you have a vision of all the above-mentioned, you can proceed to the second step – choosing the relevant algorithm.
Different kinds of AI algorithms (e.g. unsupervised learning, supervised learning, reinforcement learning) presuppose various possibilities. For instance, supervised learning algorithms, namely decision trees and linear regression, are perfect for work with labelled data. Conversely, if your data is unlabeled and you have to derive patterns within, principal component analysis or k-means clustering as unsupervised algorithms would be the most helpful.

This phase starts with choosing an Integrated Development Environment or IDE. In other words, it is a set of instruments for testing, writing and debugging code. Visual Studio Code, PyCharm and Jupyter Notebook are among the most popular options. For setting virtual environment, you would need either third-party tools (Conda or Virtualenv) or a built-in Venv module.
At this point, you have to select the library in line with your project requirements to unleash the Python benefits. Opt for the libraries with high performance, such as Pandas, NumPy and Matplotlib. After identifying data requirements, proceed with obtaining corresponding datasets from public repositories or web scraping techniques. Lastly, meticulously examine your data to identify and handle any inconsistencies, duplications or missing values.
Again, the cornerstone here is knowing what you need to achieve: different AI algorithms assist with data classification, clustering or regression. Your objective also defines performance metrics. For instance, accuracy will be your overriding criterion if you aim at data classification. The most sought-after AI algorithms encompass K-means clustering for bringing similar data points together, linear regression for getting continuous variable prediction, and decision trees for data processes related to classification.
The first tool you may utilise is the train-test split: the training subset helps the model learn data, while the testing subset estimates the performance on unseen data sets. To analyse your model’s performance, you simply compare actual values with the predicted values from the test set. In addition, using cross-validation techniques fosters accurate performance evaluation: you may partition datasets into k folds and conduct k separate training and testing processes. Every time the testing involves different folds, the rest of the data is trained. Alternatively, you may turn to a confusion matrix if your goal implies the evaluation of data classification models. A confusion matrix will visualise the predictive accuracy for every class within the dataset.
For a more detailed and in-depth review of the Python syntax and libraries, we will provide some examples. Below is a simple example of a learning model using TensorFlow in Python. This example uses the Sequential API, which is a straightforward way to build models layer by layer.
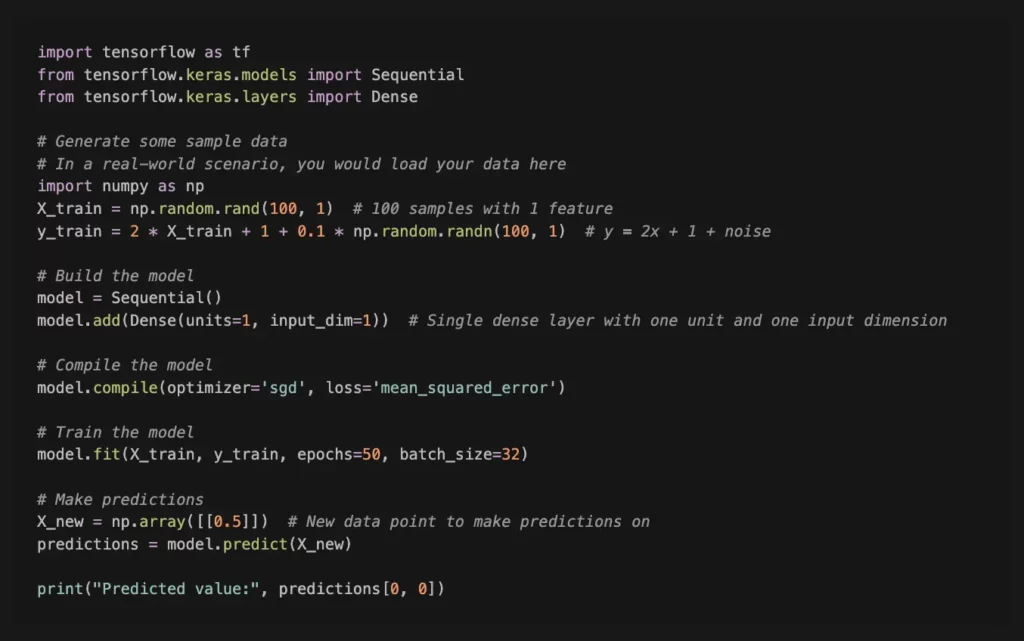
In this example, we create a simple linear regression model to predict the output (`y`) based on the input (`X`). The model is trained using stochastic gradient descent (`sgd`) as the optimizer and mean squared error (`mean_squared_error`) as the loss function. The training data consists of 100 samples with a single feature, and the target values (`y`) are generated with a linear relationship plus some random noise.
This is a very basic example, and in real-world scenarios, you may need to handle more complex data, use different types of layers, and fine-tune various parameters for better performance. Additionally, it’s essential to preprocess and normalize your data appropriately.
Natural Language Processing (NLP) – the field of AI that is heard even by ordinary users because the solution is widely distributed in various AI programs and tools. The Natural Language Toolkit (NLTK) is a popular Python library for NLP. Below is a simple example of using NLTK for text processing and sentiment analysis.
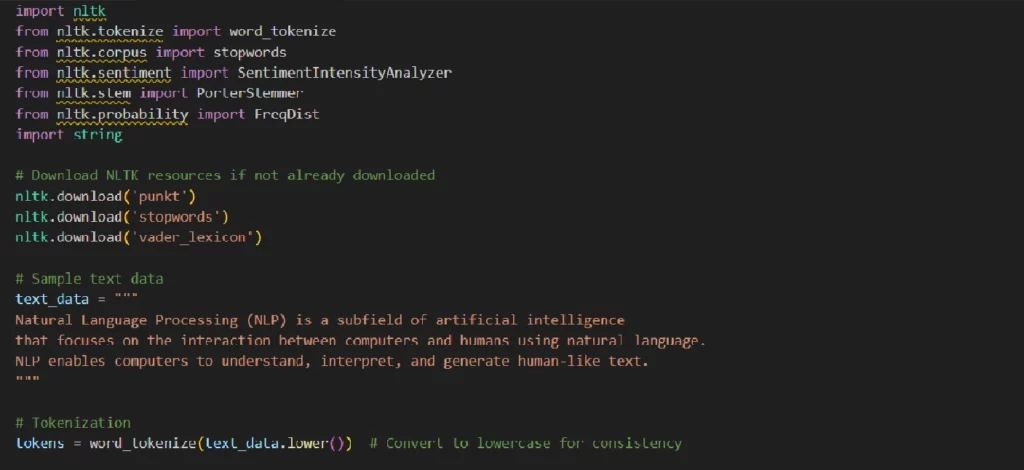
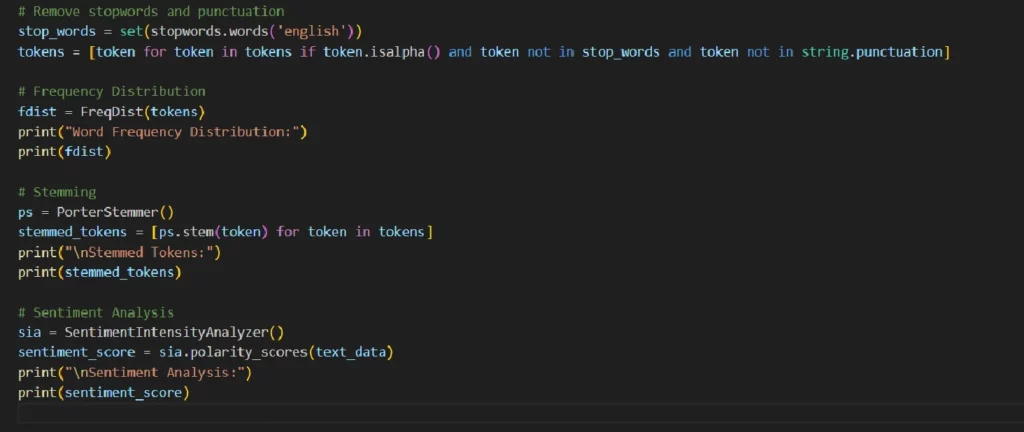
In this example, you can see the basic elements of NLP: Tokenization of the text into words; Stopwords and punctuation remover; Frequency words distribution; Words stemming; Analyse of the text’s sentiment.
Thanks to versatility, scalability, and a robust ecosystem of libraries, Python is a promising tool that efficiently works in tandem with AI. Implementing AI algorithms in Python is well-defined and consistent when keeping in mind your issue to tackle and the corresponding performance metrics.
PNN Soft will gladly help you strengthen the existing solution’s programming powers or develop an AI-based system from scratch. We have 20 years of work experience in collaborating with 150 countries, yet never stop honing our skills and analysing cutting-edge tendencies in software engineering.




